




Début novembre 2022, le Dr Lisa Su, PDG d’AMD depuis 2014, a présenté le dernier GPU de sa firme devant une foule d’invités particulièrement enthousiastes. Pourtant, contrairement à l’annonce de la gamme précédente, les slides réellement techniques et les comparatifs avec la concurrence dont la route est pavée depuis près d’un mois manquent à l’appel. Une relative opacité qui pourrait nous faire craindre le meilleur comme le pire. Essayons d’y voir plus clair.

Les Radeon RX 7900.
À l’instar de son concurrent, AMD a donc introduit sa nouvelle génération de cartes de jeu par le haut, avec la présentation des Radeon RX 7900 XTX et RX 7900 XT. La première, dont le tarif de lancement plutôt agressif est de 999 $ (comparé à celui de la RTX 4090, on entend), embarque donc un processeur graphique Navi 31 cadencé à 2,5 GHz en boost (c’est un peu plus compliqué que ça, nous allons y revenir), accompagné de six MCD portant la largeur du bus mémoire à 384 bits, une quantité d’Infinity Cache de 96 MB et 24 GB de GDDR6 20 gbps. Amputée d’un MCD, la Radeon RX 7900 XT affiche un bus mémoire 320 bits, 80 MB de cache, un GPU identique à 12 compute units près ainsi que 20 GB de mémoire vive. À 899 $, il s’agira peut-être du modèle le plus intéressant du haut de gamme AMD, grâce à son niveau de consommation « contenu » à 300 W, contre 355 W pour sa variante plus véloce.Le design de référence des cartes est une version restylée du précédent, à savoir un radiateur équipé d’une chambre à vapeur, surplombé par trois ventilateurs et complété par une backplate. Moins énergivores et imposantes que la RTX 4090, les RX 7900 se contentent de deux slots et demi et restent sur deux connecteurs PCI-E 8 broches.

Navi 31 XTX en profondeur.
AMD annonce une puissance de FP32 élevée de 61 Tflops (23 TFlops pour Navi 21) dû au remaniement des unités de calcul au sein de ses classiques compute units (CU). Elles sont désormais dénommées Dual Issue compute units et depuis la déclassification des documents internes, nous savons qu’elles ont la capacité de traiter jusqu’à deux instructions Wave32 par cycle contre une seule pour RDNA2. Navi 31 en compte 6 144, contre 5 120 pour la puce à laquelle il succède. AMD annonce un gain d’efficience d’environ 17 % par compute unit grâce à ce remaniement. Chacune d’elles embarque une unité dédiée à l’accélération hardware du ray tracing, intégrant cette fois la traversée de l’arbre BVH et non plus seulement les calculs d’intersection. Les améliorations apportées à la gestion du DXR permettraient de gagner environ 50 % de performance par CU, probablement de quoi rattraper les cartes de génération Ampere, mais sans lutter avec l’AD102, qui n’est de toute façon pas la cible de Navi 31. Autre changement architectural rapprochant un peu plus les Radeon des GeForce, des AI Matrix Accelerators font leur apparition à raison de deux par CU. Ils supportent entre autres le format de données BF16, conçu pour l’accélération des réseaux neuronaux. AMD misant sur son FSR, une technologie d’upscaling ne reposant pas sur l’utilisation de l’intelligence artificielle, nous pouvons nous poser la question de l’utilité de ces unités pour le grand public, à moins que le FSR3 ne nous réserve des surprises.
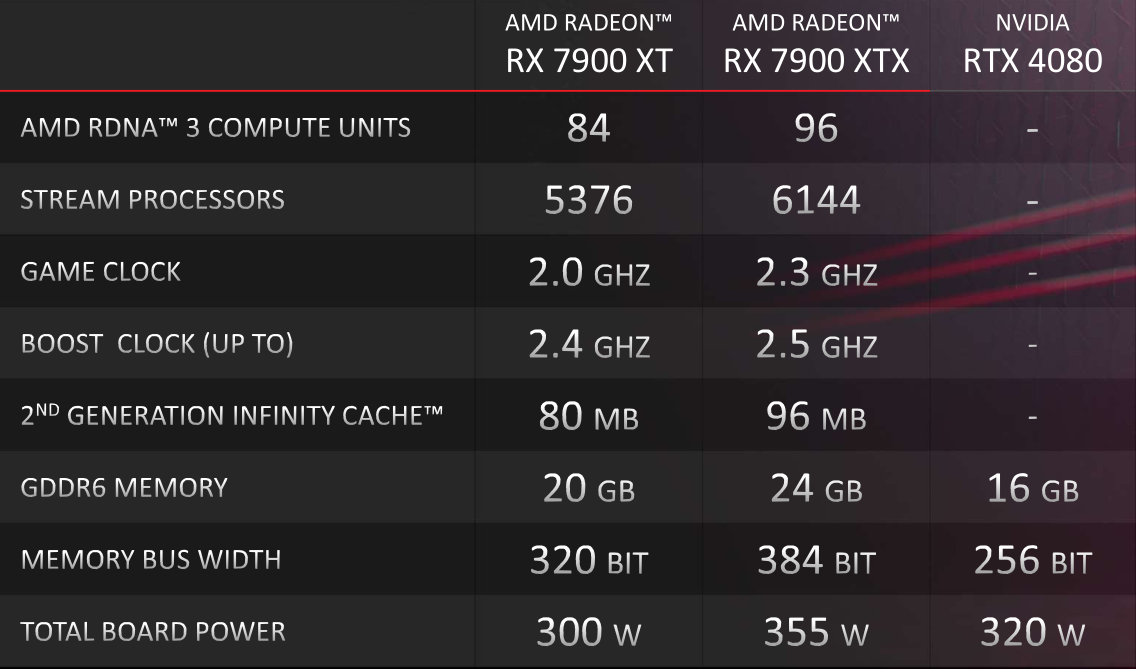
Fréquences GPU : du neuf… mais pas forcément du mieux
Sur un document détaillant le block diagram de la puce, nous pouvons lire que RDNA3 a été conçu pour dépasser les 3 GHz. Cependant, les fréquences de boost restent peu ou prou identiques à celles de la précédente génération de cartes, soit 2,5 GHz. La fréquence des Dual compute units est même découplée du reste de la puce, ces dernières tournant à une cadence légèrement moins élevée. AMD n’a pas communiqué sur les raisons de ce choix, mais on pourrait penser que le 5N TSMC n’est pas tout à fait à la hauteur de leurs ambitions.
On récapitule.
Voici les infos à retenir de la présentation de ces nouvelles Radeon : proposant un gain théorique d’environ 55 % en UHD par rapport au précédent haut de gamme, la RX 7900 XTX de référence sera lancée sous la barrière psychologique des 1 000 $ (nous ne la trouverons pas à moins de 1 000 € ici, ne rêvez pas) et incorpore tout ce que l’on attend d’une carte de jeu moderne. Moteur d’encodage AV1, Display Port 2.1, ray tracing hardware, accélération matérielle de l’IA, puissance de calcul adaptée aux très hautes définitions. Le tout, dans une enveloppe thermique identique à la génération précédente. Si AMD a comparé ses cartes à la RTX 4080 16 Go plutôt qu’à la RTX 4090 lors de la présentation, c’est parce que cette dernière devrait rester sans équivalent sur cette génération. Impossible en cette fin d’année 2022 d’obtenir les cartes et de réaliser des tests dans les temps pour le bouclage du magazine, mais ce n’est que partie remise et nous comptons bien mener des comparatifs à froid avec différentes références début 2023, lorsque les cartes seront, espérons-le, largement disponibles.


