
| Modifié le le 18 mars 2022
Une fois n'est pas coutume, débarrassons-nous tout de suite des formalités : l'architecture Turing offre des innovations intéressantes ; la GeForce RTX 2080 Ti obtient logiquement la palme de la carte-graphique-la-plus-rapide-du-moment grâce à ses performances 30 à 40 % supérieures à celles d'une 1080 Ti ; le GPU TU102 permet enfin de jouer en 4K à 60 fps avec un luxe de détail. Certes, mais le tarif des GeForce RTX est stratosphérique et il demeure de nombreux doutes quant à la pertinence d'en acheter une immédiatement. Parcourons donc ensemble les avantages et inconvénients de ces nouveaux GPU.

Jensen's About To Make You His Bitch.
Avant d'aller plus loin, permettez-moi une petite digression en guise de préambule. Afin de ne pas passer pour un infâme pro-AMD ou pour un anti-Nvidia primaire, je vous promets que je n'y reviendrai plus dans les prochains numéros. Parole ! Nvidia détient actuellement plus de 70 % du marché des gamers PC (80 % selon certaines estimations) et se trouve en situation de quasi-monopole de fait. Soyons réalistes : quoi que je puisse écrire dans ces pages, la plupart d'entre vous finiront par acheter une GeForce RTX à plus ou moins long terme, la rédaction de Canard PC également (on n'y trouve aucune Radeon depuis cinq ans) et, pour tout dire, moi aussi. Plus personne ne croit vraiment au grand retour d'AMD – en particulier dans le très haut de gamme – et seul Intel pourrait peut-être changer la donne après 2020 (mais cela reste fort improbable). Nvidia le sait et agit de plus en plus en multinationale arrogante car désormais incontournable. Presque toutes nos sources, que ce soit chez les grossistes, les revendeurs, les éditeurs de jeux, les fabricants de cartes graphiques, nos confrères et jusqu'à Microsoft décrivent les exigences toujours plus arbitraires du fabricant (avec un paroxysme au lancement des RTX). Tous acceptent de se soumettre en serrant les dents car personne ne peut désormais se passer des GeForce. Et vous aussi, clients, êtes concernés : apprêtez-vous à payer le prix fort à l'avenir puisque vous n'aurez de toute façon pas d'autre choix. Voilà où mène l'absence de concurrence. Le phénomène n'est pas isolé : Intel était exactement dans la même position il y a deux ans, se bornant à refourguer depuis des lustres de modestes Dual Core à 150 euros et des Quad Core jusqu'à 500 euros. La résurrection des CPU AMD a provoqué, en moins de 12 mois, une baisse massive des prix à performances égales. On trouve désormais des Quad Core à 100 euros et des puces à 8 cœurs pour 350 euros. Espérons que Nvidia soit rapidement soumis à une saine concurrence… et pensez-y au moment de précommander la prochaine GeForce !Nvidia détient plus de 75 % du marché GPU "Desktop" et la quasi-totalité des "Mobile".


De Pascal à Volta.
L'architecture Turing des GeForce RTX consiste en une adaptation pour le grand public de l'architecture Volta dédiée aux professionnels et sortie fin 2017. Commençons par voir les nouveautés apportées par rapport à l'architecture précédente (Pascal) des GeForce GTX 10xx. Le GPU reste scindé en plusieurs sous-blocs : on y trouve des GPC (GPU processing clusters) contenant chacun des SM (streaming multiprocessors) composés eux-mêmes de CUDA Cores. Leur organisation et la quantité totale dépendent des différentes déclinaisons. Le GPU GP102 (Pascal) des GeForce GTX 1080 Ti inclut par exemple 6 GPC, 28 SM (6 à 8 SM par GPC) et 3 584 CUDA Cores (128 par SM) et le GV100 (Volta) des Titan V embarque 6 GPC, 80 SM et 5 120 Cores (64 par SM). La première nouveauté vient du fonctionnement de ces SM. Ils peuvent désormais traiter simultanément un flux d'instructions comprenant des nombres 32-bits entiers (INT) et flottants (FP). Auparavant, c'était l'un ou l'autre. Nvidia annonce un gain faramineux dans les jeux grâce à cette fonctionnalité (jusqu'à +40 à +50 %), mais nous en doutons : de l'avis de la plupart des développeurs, les moteurs 3D n'exploitent que très peu les calculs entiers (à part pour le calcul d'adresse des textures). Mais la véritable innovation majeure apportée avec Volta vient de l'ajout de 8 Tensor Cores dans chaque SM.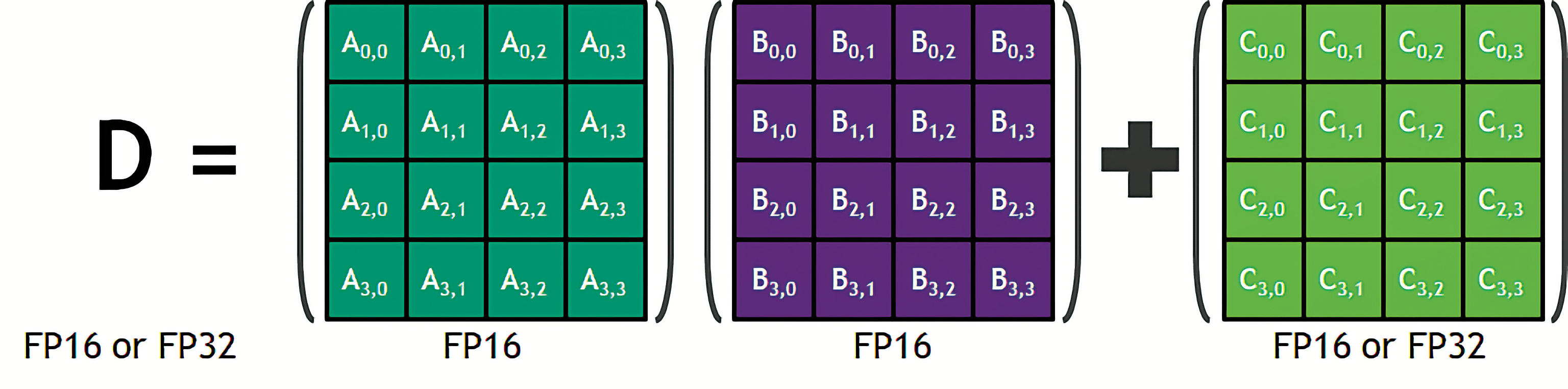

De Volta à Turing.
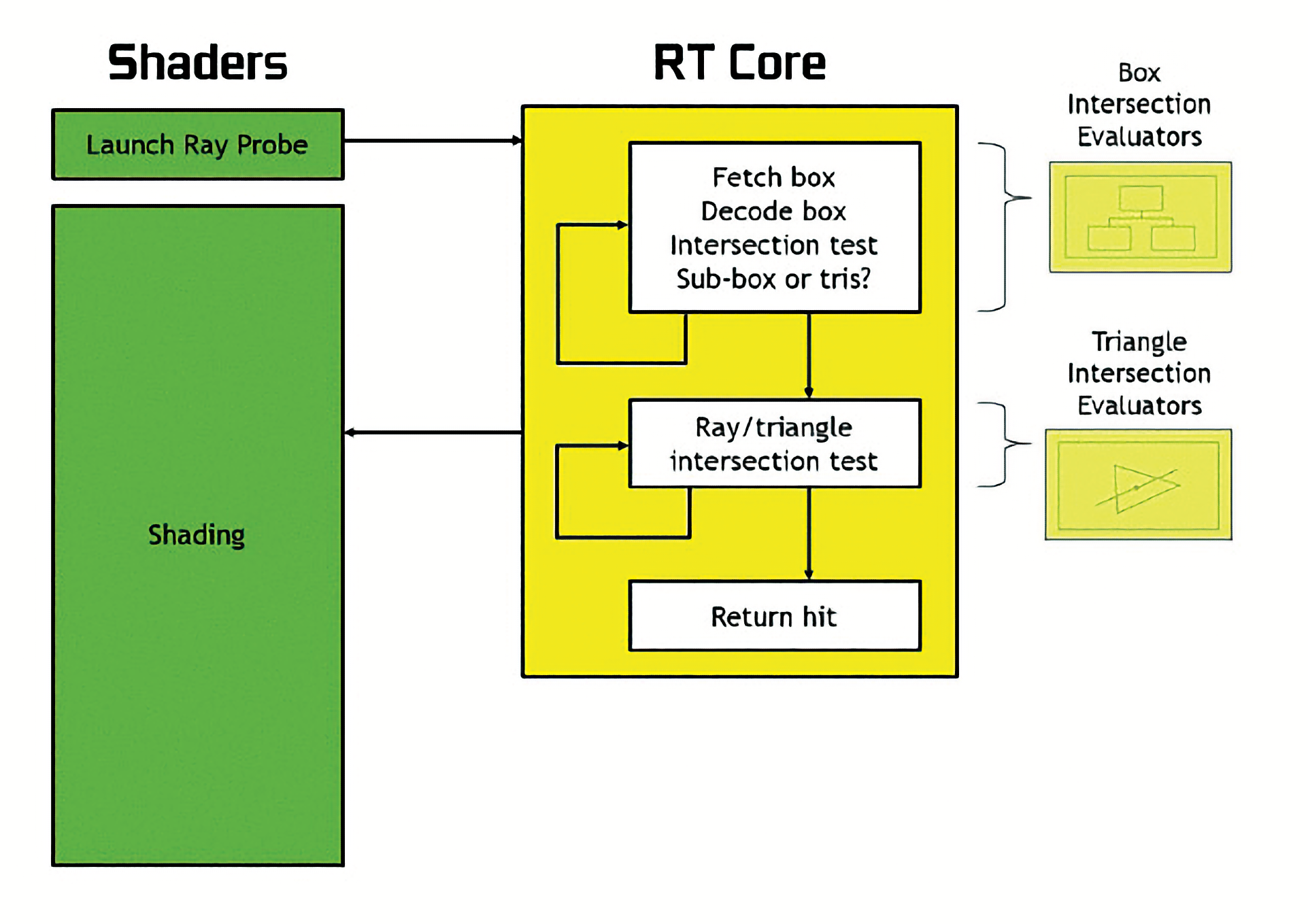
Le GPU Turing des GeForce RTX se base très largement sur Volta. Pour réduire les coûts, Nvidia a toutefois supprimé certaines fonctionnalités uniquement exploitées par le monde professionnel (comme les calculs flottants en 64 bits par exemple). La mémoire HBM2, très coûteuse, a également été remplacée par de la GDDR6 dont le mode de fonctionnement se rapproche beaucoup de celui de la GDDR5X. Nvidia indique aussi avoir amélioré son mécanisme de compression mémoire pour obtenir une meilleure bande passante efficace. Les Tensor Cores ont également évolué pour permettre les opérations sur des matrices de nombres entiers à 8 et même 4 bits (en plus des flottants 16 et 32 bits). Certains modèles de Deep Learning pourraient à l'avenir exploiter une précision ultra faible de ce type. Jusque-là, il s'agit d'évolutions assez mineures entre Volta et Turing. Le plus gros changement selon le White Paper vient de l'ajout dans les SM d'une unité baptisée "RT Cores", qui viendrait en plus des CUDA Cores classiques et des Tensor Cores inaugurés avec Volta. Et là, il y a un flou.
TU102 à TU106.
Parlons maintenant des différents GPU disponibles. Le fleuron de la gamme, le TU102, est un mammouth souffrant d'obésité morbide : il embarque 18,6 milliards de transistors sur une surface de 754 mm². À titre de comparaison, le GP102 de la GeForce GTX 1080 Ti en intégrait 12 milliards sur 471 mm². Le die est donc 60 % plus gros ! Vu l'augmentation somme toute modeste du nombre d'unités de calcul classiques (3 584 -> 4 352, soit +20 %), on en déduit que les Tensor Cores et les autres optimisations représentent une part très importante du GPU. Gravé avec le process 16++ nm de TSMC (et non pas en 12 nm comme l'explique le marketing), le TU102 consomme au final plus que le GP102 (260 W). En pointe, il peut même dépasser les 300 W. Un die aussi énorme coûte une fortune à produire : sur un wafer classique de 300 mm, on ne peut caser que 70 GPU ! Nvidia proposera dès octobre trois GPU :• TU102 (GeForce RTX 2080 Ti) : il embarque 4 352 unités de calcul CUDA et 544 unités TC cadencées à 1.35 GHz de base (1.63 GHz Turbo) ainsi que 11 Go de GDDR6 à 1.75 GHz (14 Gbps) sur un bus 352 bits pour une bande passante totale de 616 Go/s.
• TU104 GeForce RTX 2080) : On y trouve cette fois 2 944 unités de calcul CUDA et 368 unités TC cadencées à 1.52/1.80 GHz et 8 Go de GDDR6 à 1.75 GHz (14 Gbps) sur un bus 256 bits. La bande passante mémoire s'élève à 448 Go/s. Le GPU est aussi plus "petit" bien qu'il reste plus imposant que le GP102 de la 1080 Ti : 545 mm². Son TDP atteint les 225 W.
• TU106 (GeForce RTX 2070) : Prévu quelques semaines après les deux précédents, il contiendra cette fois 2 304 unités de calcul CUDA et 288 unités TC cadencées à 1.41/1.71 GHz et la même mémoire que le TU104. Avec un TDP de 185 W et une taille de die de 445 mm² pour plus de 10 milliards de transistors, il s'agira toujours d'un très gros GPU.
À noter que les fréquences mentionnées ci-dessus sont celles des Founders Edition. Les cartes graphiques de fabricants tiers sont cadencées de 50 à 100 MHz de moins en mode Turbo. Nvidia fournit toutefois un utilitaire spécifique qui permet de déterminer le profil d'overclocking maximal pour toutes les cartes. Le processus dure 20 minutes environ.




